Search code, repositories, users, issues, pull requests...
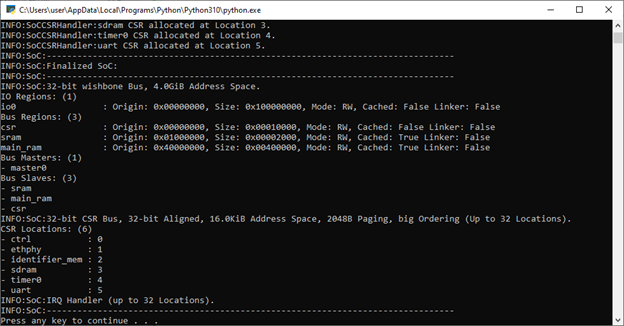
Продолжая рассказывать про курсы Apache Spark для разработчиков на практических примерах, сегодня рассмотрим, как кэширование данных позволяет оптимизировать распределенные вычисления в этом Big Data фреймворке. Читайте далее, как ускорить выполнение запросов в Spark SQL , чем отличаются функции cache и persist , из чего состоит план запроса и каковы альтернативы кэшированию данных для повторного использования вычислений. Кэширование данных в Apache Spark SQL — это весьма популярный способ повышения производительности приложения за счет повторного использования некоторых вычислений. Однако, чтобы эффективно использовать его, следует помнить о некоторых особенностях настройки Spark-приложений.











Выполните обновление до Microsoft Edge, чтобы воспользоваться новейшими функциями, обновлениями для системы безопасности и технической поддержкой. Некоторые сведения относятся к предварительной версии продукта, в которую до выпуска могут быть внесены существенные изменения. Майкрософт не предоставляет никаких гарантий, явных или подразумеваемых, относительно приведенных здесь сведений.







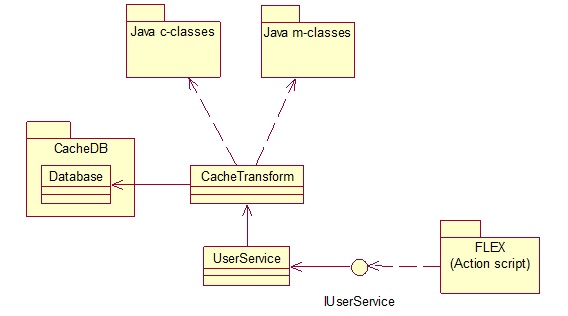
Проблема в том, что из файла контроллера запрашивается строка вида " product. А в метод get класса Cache приходит непонятно почему такая строка: " product. При этом метод set класса Cache записывает кэш как и положено - в виде файла с именем " product.